



Technohumanism: technology, education, and human value
When technology doesn’t replace people, but empowers them.
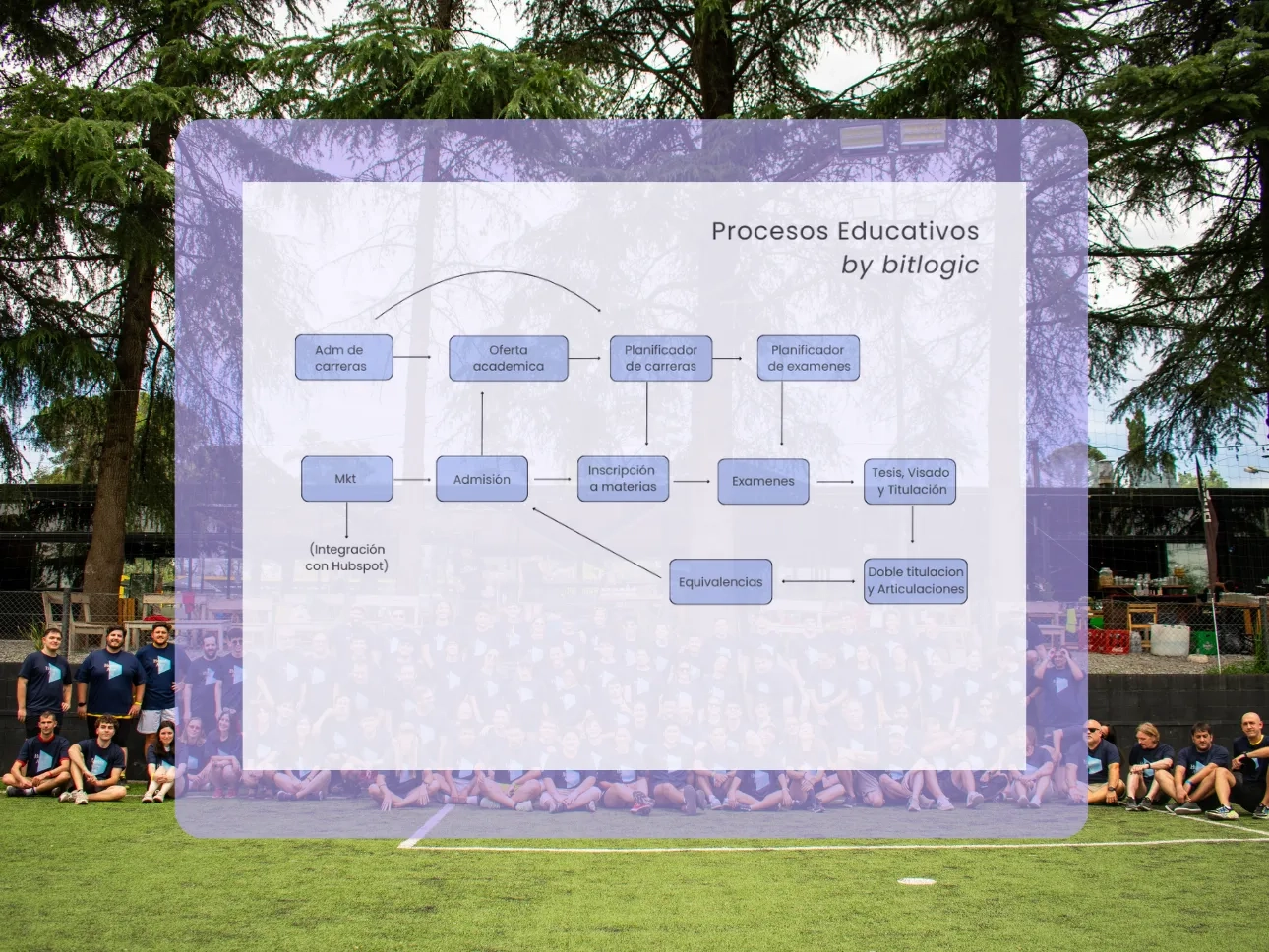
We drive the digital modernization of educational institutions through the design, engineering, and agile development of software solutions built to transform academic management, empower educators, and support every student throughout their academic journey. We do it with closeness, empathy, and a clear conviction: education isn’t just coded—it’s imagined, designed, and built together.
“aprendiz works like a ‘home tutor,’ answering questions instantly.” — Dr. Lillian Acuña Olivares, Academic Secretary, Andrés Bello University (Chile)
"Bitlogic delivered a comprehensive digital transformation, empowering us to move forward into the future of education." Hugo Colombatto, IT Director, University Siglo 21.
Students now enjoy a seamless, high-speed learning experience with no interruptions—strengthening TECLAB’s leadership in online education.
"We like Bitlogic for its teamwork in reaching goals. We appreciate the quality of their work and their technical skills. We also value the strong relationship they build with clients." - OEC-
"With Bitlogic, we found availability in addressing our inquiries and constant support." Yamil Alejandro Rabbat, Co-Founder & CEO, Ed Machina.
“From the very beginning, we were impressed by their professional approach and their commitment to meeting deadlines.” Jorge Eduardo Silvestre, Product and Operations Manager, Benchlab.
We are strategic AWS partners for the education sector and proud partners of Instructure, the world’s leading learning platform provider.
For us, being an EdTech company is about much more than building technology for education. Innovation alone doesn’t create impact if millions of students are still facing the same challenges—dropout, inequity, and disconnected systems. At Bitlogic, we believe education must evolve.
That’s our purpose.
We are EdTech leaders, developing people-centered solutions grounded in deep educational expertise—transforming complexity into simplicity and fragmentation into connection.
We believe technology should not replace what’s human, but amplify it. That data isn’t just numbers, but a compass that helps guide every student toward their best future.
Our role is clear: to be the strategic partner that helps educational institutions take the next leap forward. We’re building the future of education.
Technology Evolves. Humanity Remains
Jesi, Solution Architect
When technology doesn’t replace people, but empowers them.
When technology understands education.
How AI & ML help us act earlier, understand better, and provide stronger support.